LEFT JOIN
20 March 2024 08:30
Microsoft BI уходит из России
И не только он.
🔜 Клиенты Microsoft получили письма счастья, где компания предупредила их, что с 20 марта прекращает поставки ПО для российских клиентов, включая облачные решения. Какое именно ПО затронут эти изменения, не уточняется, но, согласно самой популярной версии, мы останемся без Power BI, Dynamics CRM, Microsoft 365 и Outlook.
Что ж, сегодня узнаем точно.
За последние два года многие компании уже перешли с Microsoft на российские и open source-аналоги. Но все же кто-то продолжал пользоваться ее сервисами — например, те, у кого подписки были оплачены на несколько лет вперед. С сегодняшнего дня они потеряют доступ к сервисам Microsoft и всем данным, которые там хранились.
А как у вас? Вас затронуло это решение Microsoft или вы отказались от их услуг? А может, и не пользовались никогда? Делитесь в комментах, как вы теперь будете жить без Power BI и Outlook! 👀
Upd. А вот и список продуктов, к которым Microsoft ограничивает доступ — всего 50 штук, включая Power BI, OneDrive, Microsoft 365 и Azure.
Читать полностью…
LEFT JOIN
18 March 2024 08:30
Row Zero: как Excel, только в 100 раз быстрее
Row Zero — новый облачный инструмент для работы с данными, который среди аналогов выделяется тем, что умеет быстро обрабатывать очень большие объемы данных.
🔵 Интерфейс, как у всем знакомого Excel. Он понимает такие же формулы, умеет делать таблицы и визуализировать данные. Не Tableau, но график нарисует.
🔵 В него можно загружать CSV и JSONL-файлы или напрямую подключать к источникам данных — базам, хранилищам, аккаунтам в соцсетях, рекламным кабинетам и так далее.
🔵Не боится ни файлов весом в несколько ГБ, ни миллионов строк и столбцов. На официальном сайте уверяют, что он в 1000 раз шустрее Google Sheets.
🔵 И все это в облаке — то есть легко расшарить для совместного просмотра или редактирования.
Убедиться, насколько правдивы обещания разработчиков, можно прямо сейчас, бесплатно и без регистрации и без смс. У бесплатной версии есть свои ограничения, но оценить полезность инструмента она позволит.
Читать полностью…
LEFT JOIN
14 March 2024 08:31
TimeGPT: нейросеть для анализа временных рядов
Когда речь заходит про нейросети, большинство вспоминает про ChatGPT, Midjourney, Stable Diffusion, Sora и так далее.
У них функционал все более впечатляющий с каждой новой версией и одновременно понятный: генерация текстов, изображений и видео по запросу. Их уже используют в самых разных сферах — создают рекламные креативы, «прикручивают» к чат-ботам, пишут дипломы.
Но ИИ используется и для более узких, специализированных задач. Пример: TimeGPT — модель, которая анализирует временные ряды.
🔜 Временной ряд — это последовательность значений показателей, изменения которых фиксировались в течение определенного промежутка времени. Например, биржевой курс доллара.
Анализ временных рядов используется, чтобы составить прогноз изменений, выявить тенденции и закономерности. Это непростая задача, которая решается с помощью сложных математических моделей. Неудивительно, что появилась ИИ-альтернатива, которая призвана сделать анализ временных рядов быстрым и доступным.
Ее предложила компания Nixtla
💬 TimeGPT — модель, натренированная на датасете из более чем 100 млрд показателей. Данные брали из открытых источников.
💬 Ее можно файнтюнить на своих данных, чтобы улучшить результаты, но авторы заверяют, что она и без этого справляется. То есть, TimeGPT можно дать набор данных, которые она никогда раньше не видела, и она составить по ним прогноз и выявит аномалии.
💬 Авторы сравнили TimeGPTс 10+ различных альтернатив, и почти во всех случаях ее прогнозы были точнее. Правда, они не стали сравнивать ее с самыми популярными методами для анализа временных рядов — моделью ARIMA и Prophet из-за сложности и ресурсоемкости.
Подробнее про бенчмарк, а также саму модель и ее архитектуру они рассказали в своей работе на arxiv.org.
Сейчас TimeGPT находится в бете — нужно подать заявку, чтобы принять участие в тестировании. Но уже доступны несколько open source-инструментов, которые умеют предсказывать погоду и изменения экономических показателей.
Читать полностью…
LEFT JOIN
12 March 2024 10:31
Идти в IT
Первым программистом — точнее программисткой — была математик Ада Лавлейс. В XX веке программирование долгое время было преимущественно женской профессией — в основном, потому что требовало усидчивости и внимательности, которые традиционно считались «женскими» чертами.
Со временем ситуация изменилась, и сейчас в IT работает намного больше мужчин — в России их доля составляет 74%.
Постепенно этот показатель меняется, все больше девушек и женщин выбирают карьеру в IT. Компания Smartex и организация Women in Tech Russia запустили проект «Идти в IT?», где собрали истории 62 участниц, выбравших карьеру в этой отрасли.
Они рассказали, кем они работают и как пришли в профессию, с какими трудностями сталкивали и как их преодолевали. И, кстати, там есть история нашей коллеги из Valiotti Analytics — Регина! ❤️
Проект был приурочен к 8 марта, но мы считаем, что про такие классные, вдохновляющие инициативы стоит рассказывать круглый год. 🔥
Читать полностью…
LEFT JOIN
08 March 2024 08:30
Как нейросети помогают изучать историю
Мы уже рассказывали про преподавателя истории Бенджамина Брина, который нашел любопытное применение ChatGPT. Он использовал нейросеть как тренажер для своих студентов, где те моделировали ситуации из прошлого — например, из охваченного чумой Парижа. Они должны были проанализировать историческую достоверность симуляции и написать про это эссе.
Еще в сентябре Брин отметил рост заинтересованности в учебе со стороны студентов. А теперь у него накопилось достаточно данных, чтобы подтвердить свои слова статистикой.
🔵 59% студентов отметили, что стали больше интересоваться его предметом, а для 40% учеба стала намного интереснее. Только 1 человек из опрошенных сказал, что наоборот потерял интерес.
🔵 Когда их спросили, что им понравилось больше всего, 71% выбрали вариант «возможность принимать решения как участник исторических событий».
🔵 84% заявили, что ИИ-симуляции помогли им лучше понять исторический период, который они изучали.
Главной проблемой этого подхода так и остается точность симуляций. Хотя Брин верит, что этот недостаток можно будет со временем преодолеть.
💬 Он приводит в пример попытки заставить LLM разыграть из себя врача из 17-го века. Сначала Брин поэкспериментировал с моделью MonadGPT, которая по словам авторов, дает ответ на вопрос «Что было бы, если бы ChatGPT появилась в 17-м веке?» Потом попробовал сам научить ChatGPT давать ответы, как доктор из этой эпохи, то есть назначать лекарства, которые использовались в то время. В обоих случаях модели дали реалистичные, пусть и неидеальные ответы.
Возможно, нам и не надо стремиться к идеальной точности. Главное достоинство нейросетей — в том, что они помогают подстегнуть воображение и по-новому взглянуть на знакомые темы. Они не замена привычным способам обучения, а просто новый инструмент для преподавателей, ученых и писателей.
Читать полностью…
LEFT JOIN
06 March 2024 10:31
UNION ALL: конференция Yandex Cloud про технологии для работы с данными
Конференция пройдёт 20 марта: на одной площадке объединятся эксперты из разных областей, чтобы поговорить про аналитику, облачные технологии, ML и многое другое.
Всего будет 2 трека — про кейсы и про технологии.
🔵 На первом спикеры поделятся опытом и лучшим практиками для работы с данными и построения дата-проектов в облаке — от создания корпоративных хранилищ данных до построения систем скоростной аналитики.
Среди приглашенных экспертов — представители банка, крупных ритейлеров, цифровых платформ и общепита. Так что кейсы будут максимально разнообразные.
🔵 На втором треке сотрудники Yandex Cloud расскажут про эффективные решения для работы с данными и поделятся последними обновлениями в сервисах. Из актуальных тем - безопасность хранения данных в облаке, последние новости по сервису для визуализации данных DataLens, возможности и сценарии для решения ML-задач.
🔥 А еще в конце мероприятия будет секретный доклад — даже мы пока не знаем, про что он будет!
Конференция пройдет в Москве на территории «Синема Парк Мосфильм», но присутствовать лично необязательно — можно и онлайн.
Обязательна только предварительная регистрация 🔜
Читать полностью…
LEFT JOIN
01 March 2024 08:40
Basedash: дашборд за 10 минут
Еще один инструмент на основе ИИ, который позволяет работать с данными без кода — или почти без кода. Basedash подключается к БД и генерирует интерфейсы для взаимодействия с ней.
💬 Это может быть дашборд, CRM или целая админка, которая позволяет редактировать, добавлять или удалять данные.
💬 Все это приложение умеет делать без кода, но при желании можно писать SQL-запросы самостоятельно или с помощью ИИ-ассистента.
💬 Basedash работает с PostgreSQL, MySQL, MariaDB, SQL Server и Redshift, а также позволяет подключать API сторонних сервисов, чтобы подтягивать информацию из них.
💬 Созданный в Basedash интерфейс можно расшарить с другими людьми и раздать разные уровни доступа. Настройки довольно гибкие: можно ограничить возможности для просмотра или редактирования данных, выборочно скрыть часть информации на дашборде или вообще спрятать его за двухфакторной идентификацией.
Главное преимущество — экономия времени. 🔥 Команда проекта обещает, что собрать дашборд в Basedash получится в 100 раз быстрее, чем если делать его самостоятельно. Правда, нигде не написано, как они это посчитали.
Так или иначе, это потенциально интересное решение, особенно для небольших команд, у которых нет ни ресурсов, ни необходимости, чтобы делать использовать более сложные инструменты.
Читать полностью…
LEFT JOIN
28 February 2024 11:40
Как и зачем мы сделали три дашборда по LinkedIn
💙 LEFT JOIN — это не просто канал в телеграме и оператор в SQL. Это один из множества проектов нашей команды. Кроме него, есть еще одноименный блог, канал на Youtube и несколько аккаунтов в разных соцсетях. Только в LinkedIn аж три разных профиля.
В общем, мест в Интернете, где мы постим всевозможный полезный контент про данные, аналитику, AI и новости IT довольно много. За ними надо следить, мониторить, как аудитория растет и реагирует на разные публикации. Никто не хочет постить что-то, что совершенно не будет цеплять аудиторию.
Когда аккаунтов много, собирать информацию про их успехи вручную становится неудобно и неэффективно. Так мы решили сделать дашборд в Tableau, чтобы вся нужная информация подтягивалась автоматически и отображалась на графиках.
🔜 И это оказалось не так уж и просто, но интересно! Все подробности — в новой статье в блоге.
🔵 Делали для себя, но как для клиента ровно по тому же алгоритму. Подготовились, узнали про возможности и ограничения площадки, провели серию интервью с пользователями.
🔵 Столкнулись с тем, что тянуть данные с личных аккаунтов в LinkedIn намного сложнее, чем с корпоративных. Для таких задач мы обычно используем инструмент Fivetran, но он работает только со страницами организаций. Сервисы, специально заточенные под личные аккаунты, спустя какое-то время начали требовать капчу, которую надо вводить руками. Это шло вразрез с желанием автоматизировать эти процессы, так что пришлось создать решение самостоятельно.
🔵 Дашбордам всего несколько месяцев, но результаты они уже принесли. Мы уже составили портреты ЦА и увидели, какие темы заходят подписчикам лучше всего.
Читать полностью…
LEFT JOIN
26 February 2024 09:09
Зачем кому-то сидеть в Тиктоке?
Этим вопросом задаются многие люди старше 30 лет, и наконец-то наука нашла ответ.
Авторы исследования взяли 1000 студентов американского вуза и спросили, за какую сумму те будут согласны на 4 недели деактивировать свои аккаунты в соцсетях. Они сравнили, как менялись ответы в зависимости от условий: если друзья опрошенных тоже уходили с этих сайтов и если они продолжали на них сидеть.
🔜 Оказалось, что люди просили на 33% больше денег, чтобы временно уйти из Тиктока, если их знакомые не делали этого. То есть чем больше людей вокруг сидят в соцсети, тем сложнее отказаться от нее.
🔜 Также спрашивали, сколько человек сам заплатил бы за то, чтобы его знакомые ушли из соцсетей. Те, у кого не было своих аккаунтов были готовы отдать примерно в 2 раза больше денег, чем те, у кого они есть.
🔜 Исследователи пришли к интересному, но немного печальному выводу. Хотя многие юзеры не видят пользы в соцсетях, им кажется, что отказ от них принесет больше вреда.
Вот так графики показали, что вынуждает людей листать бесконечную ленту с фотками и видео с котами — неумолимое давление со стороны окружения.
Читать полностью…
LEFT JOIN
21 February 2024 08:30
Данных стало слишком много
Уже даже Большому Брату следить за нами становится тяжеловато.
Bloomberg рассказал про нелегкие будни американских шпионов. Казалось бы, причем здесь данные?
🔵 Раньше главной проблемой было достать секретную информацию об объекте слежки. А сейчас — извлечь крупицы пользы среди огромных объемов доступных данных. Их стало так много, что обработать их силами обычных людей становится невозможно.
🔵 Большинство из нас оставляют за собой цифровой след. Посты в соцсетях, данные о местоположении, которые собирают разные приложения, или о покупках и переводах. А еще фотографии, видео, аудио…
🔵 Это потенциально ценная информация о человеке, часть которой еще и лежит в открытом доступе. Но ее настолько много, что для того, чтобы извлечь из нее, как сейчас модно говорить, инсайты, правительству США даже пришлось обратиться к ИИ.
🔵 Задачу усложняет то, что все эти данные собирают разные департаменты и делают это по-своему. Они не всегда делятся находками друг с другом, по-разному их обрабатывают и хранят. Так что мало найти данные — надо их еще как-то скоординировать между собой.
Скажите ведь, звучит это все на удивление жизненно? Гора разрозненных данных из кучи источников, все по отдельным табличкам, и никто толком не понимает, где что лежит и как это собрать в кучу. 👀
В следующий раз, когда столкнетесь с чем-то подобным, можете успокоить себя тем, что это проблема не уникальная, а общечеловеческая и не чуждая даже американской разведке.
Читать полностью…
LEFT JOIN
19 February 2024 09:18
Токсичные комментарии отравляют интернет
Анонимность в интернете развязывает руки, и люди часто пишут здесь вещи, которые в лицо оппоненту не сказали бы. И это может приносить реальный вред не только отдельным юзерам, но и целым ресурсам.
💬 Команда ученых проанализировала 57 миллионов комментариев к 8,5 миллионам правок к статьям на «Википедии». Они ограничились 6 самыми активными версиями ресурса — английской, немецкой, французской, испанской, итальянской и русской.
Они сравнивали активность пользователей, получивших токсичные и нетоксичные комментарии к своим правкам. Оказалось, что у первых она была ниже в течение следующих 100 дней. Также увеличивался риск того, что пользователь вообще покинет сайт.
Почему это проблема?
💬 «Википедия» — это результат коллективного труда множества пользователей. Только у англоязычной версии больше 120 000 активных юзеров, которые пишут, правят и дополняют статьи.
В основе проекта лежит прекрасная идея, но он не лишен проблем и конфликтов. В частности, знаменитых «войн правок», когда одни пользователи вносят информацию в статью, другие ее удаляют, потом первые возвращают обратно. Это может продолжаться долго и сопровождаться обменом любезностями в комментариях.
Для любопытствующих — на «Вики» даже есть отдельная статья про самые дурацкие войны правок.
💬 Может показаться, будто это не стоит принимать всерьез. И есть люди, которых никакие комментарии действительно не задевают.
Но мы тут не про частности, а про данные. И вот они показывают, что в масштабах всего сообщества проекта снижение продуктивности очень серьезное. «Вики» теряет не просто человекочасы, а целые человекогоды пользовательской активности. Меньше всех страдает русскоязычная версия — у нее выпадает всего 5 лет, тогда как у англоязычной — 265. И это важно для проекта, который по своей сути полагается на вклад пользователей.
А вывод какой? Уже даже статистика говорит, что не надо писать токсичные глупости в интернете — он от этого портится. ❤️
Читать полностью…
LEFT JOIN
14 February 2024 08:51
Пост любви к оконным функциям
Когда еще признаваться в любви к SQL, если не сегодня? ❤️ Хоть каждый день — скажете вы и будете правы, но на этот раз у нас есть особый повод. Даже два.
Сегодня вы сами знаете какой день, а 17-го — день рождения основателя Valiotti Analytics и автора канала Николая Валиотти! В честь этого с 14 по 17 февраля подписаться на нашу рассылку по оконным функциям можно за 1490₽ вместо 4990₽.
Что за функции такие?
Они позволяют работать с выделенными наборами данных в таблице — окнами. В рамках окна данные можно сортировать, ранжировать, находить средние, минимальные и максимальные значения и так далее.
Информации про них много, но часто написана она сложно. Мы решили исправить эту ситуацию и в конце года запустили свой курс по оконкам в формате email-рассылки.
🔜 8 писем про оконные функции, фреймы RANGE и ROW и красивые оптимизированные запросы.
🔜 Дополняем теорию практикой и наглядными примерами реальных бизнес-задач.
🔜 Для новичков в SQL — это понятный материал для знакомства со сложной темой, для более опытных аналитиков — возможность структурировать знания и заполнить пробелы.
Подписывайтесь, знакомьтесь с прекрасным миром оконных функций и любите SQL! ❤️
Читать полностью…
LEFT JOIN
12 February 2024 10:00
Dactilo: превращаем клавиатуру в печатную машинку
Как-то раз мы писали про приложение на Mac, которое во время нажатия на клавиши выдает через динамики щелчки механической клавиатуры. Вариант специально для тех, кому не нравится печатать на слишком тихих клавиатурах Apple.
🔜 На GitHub нашлось кое-что поинтереснее (и погромче) — daktilo. Это приложение позволит чувствовать себя Хемингуэем, создающим очередной шедевр, когда вы просто пишете код или отправляете комментарий в интернете. Оно выдает звуки печатной машинки — автор не забыл даже при «дзынь!» при переходе на новую строку.
Приложение бесплатное и доступное всем — поддерживает Windows, Mac и Linux.
Самое то, чтобы принести ноутбук в людное место, выкрутить звук на максимум и начать творить. 🔥
Читать полностью…
LEFT JOIN
08 February 2024 08:31
Как пароли делают наши жизнь неудобнее: от Книги Судей до настоящего времени
В армии Древнего Рима специально назначенные люди — тессерарии — передавали солдатам от командования пароли на глиняных табличках. Пароль, который менялся каждый день, надо было очень постараться не забыть, чтобы не получить мечом по голове от караульного. 👀
В течение последующих пары тысяч лет способы аутентификации усовершенствовались, стали надежнее и немного дружелюбнее к пользователю. По крайней мере, теперь у нас есть кнопка «Забыли пароль?»
🔜 Но стали ли они удобнее? Иногда кажется, что нет
История развития способов аутентификации — это история борьбы между безопасностью и комфортом. И если в Древнем Риме о последнем не особо заботились, то сейчас необходимость постоянно выдумывать, менять, запоминать или где-то хранить все более сложные пароли многих раздражает.
К такому выводу пришел автор одного субъективного, но логичного рейтинга методов подтверждения личности, к которым люди прибегали на протяжении веков. Да, веков — он начал с библейской Книги Судей и уже упомянутого Древнего Рима, а закончил современной многофакторной аутентификацией.
Сам он ждет наступления счастливого беспарольного будущего. А что думаете вы? Пароли из минимум n символов с буквами, цифрами и спецсимволами — необходимость или пережиток?
Читать полностью…
LEFT JOIN
06 February 2024 08:40
А вы часто ходите в музеи?
Есть риск, что не очень, даже если хотели бы. Времени на такие развлечения у многих современных людей нередко совсем не остается.
Но прогресс на месте не стоит, и некоторые музеи вполне возможно посетить, не выходя из дома или офиса. И нет, мы не про 3D-туры по Лувру, хотя это тоже достойный способ провести время.
Музей интернет-артефактов — это возможность приобщиться к истории интернета, начиная от арпанета. В каталоге — первый смайлик и первый набор эмодзи, ранние смешные версии Википедии или сайта Netflix, хакерский словарь из 1983-го и тому подобные памятники эпохи. Для кого-то это повод ностальгировать и вспомнить интернет, которого уже нет, для кого-то — возможность увидеть хотя бы так, как все было раньше. 👀
🔥 Приятный бонус — все экспонаты можно потрогать, то есть, понажимать на кнопочки и поскролить винтажные странички сайтов прошлого.
Читать полностью…
LEFT JOIN
19 March 2024 10:32
Работа с данными в очень больших командах
Большая компания — это не только хорошая зарплата и узнаваемое название, которое не стыдно назвать, когда вы рассказываете, где работаете. Это еще и любопытная корпоративная культура и организация внутренних процессов. Нельзя вырасти от стартапа до энтерпрайза, сохранив задор и открытость, что были в начале. Особенно интересно, как рост компании влияет на дата-команды.
Нашли две любопытных статьи на эту тему. Первая — про проблемы.
🔵 На ранних этапах пайплайны по работе с данными выстраивает небольшая команда, а то и один инженер.
🔵 Со временем объемы растут, данных становятся больше, а запросы заказчиков вроде маркетинга — сложнее. ИТ-инфрастуктура расширяется и меняется, и это приводит к непредсказуемым последствиям: например, дашборды ломаются и начинают показывать неактуальные данные. Падает скорость работы и качество взаимодействия между командами.
🔵 Пока дата-инженеры пытаются разобраться в проблемах (которые создали не они!), копятся ошибки, а доверие пользователей к данным падает.
🔵 Начинается поиск решения — например, перебор новых инструментов и платформ для работы с данными или попытки реорганизации. Это может принести результат, но не устранит причину проблемы.
И что делать?
На этот счет высказался CEO dbt — фреймворка для трансформации данных. Его пост в основном опять про проблемы дата-команд, а еще возможности dbt. Это тоже интересно, но нам нужен последний абзац про то, что ждет нас в будущем.
🔜 А будущее за командами, которые становятся владельцами своих данных и полностью отвечают за все, что связано с их хранением, трансформацией и т. д. Для коллег из других команд они создают витрины данных: так те смогут получить нужную информацию о показателях и метриках, не погружаясь «вовнутрь».
Так огромный и все увеличивающийся массив информации разбивается на несколько отдельных проектов, у каждого из которых есть владельцы — конкретные люди, отвечающие за то, чтобы все работало как надо. А не бедные инженеры, которые бегают и тушат чужие пожары. 👀
Читать полностью…
LEFT JOIN
15 March 2024 08:43
Почему вы нас читаете?
Ну а теперь к главному вопросу, которым задаемся не только мы. Недавно увидели вот такой пост:
За кем следят продуктовые и дата-аналитики
Ребята из NEWHR Data сформировали рейтинг профильных экспертов, Telegram-каналов, Youtube-каналов и подкастов, за которыми следят продуктовые и дата-аналитики.
…я лично никогда не понимал, почему у LEFT JOIN так много подписчиков и почему их читают. А они вот вторые в рейтинге.
👀 И подумали: и правда, почему вы нас читаете-то, дорогие подписчики?
Поделитесь в комментариях!
Читать полностью…
LEFT JOIN
13 March 2024 08:34
Да кто такой этот ваш SQL
Пост для начинающих аналитиков, BI-специалистов и всех, что хочет подтянуть знание SQL. Делимся проверенными курсами и тренажерами, которые помогут освоить основы.
🔵 Марафон данных: первое знакомство с SQL и Python на «Степике». Это проект нашей команды, которым мы очень гордимся. Курс не только знакомит студентов с SQL и Python, но и позволяет почувствовать себя в роли аналитика. Студенты выполняют задания, похожие на реальные задачи, с которыми имеют дело специалисты на практике. Это возможность поближе взглянуть на профессию и понять ее специфику. Не можем не похвастаться: его прошли уже больше 12 000 студентов!
🔵 Интерактивный курс по SQL от SQL Academy. Начинаем с самых основ и доходим до довольно продвинутых вещей. Большой плюс — платформа удобная, а материал подается максимально понятно и логично. Отличный вариант для тех, кто вообще ничего про SQL не знает и изучает его с нуля.
🔵 Симулятор SQL на Karpov.Courses. 150 задач, которые помогут научиться говорить сразу на двух языках: на SQL и языке бизнес-запросов, с которыми к аналитикам приходят заказчики и коллеги.
🔵Интерактивный тренажер по SQL. Еще один курс на «Степике», который знакомит с практикой и предлагает решать задачи, похожие на «боевые». Главный плюс — очень много заданий в каждом модуле. Набьете руку так, что сможете писать SQL-запросы с закрытыми глазами.
🔵 SQL-Ex. Возможно, один из самых старых сайтов про SQL в рунете, собравший впечатляющую базу упражнений. Он выступает в первую очередь не как курс или учебник, а как тренажер — то есть, чтобы пользоваться им, нужна какая-никакая теоретическая база. Хотя если вдруг что-то забыли, под задачами есть ссылки на туториалы.
🔵 ITResume. Прошли все курсы и прорешали задачи в тренажерах? Ну все, можно искать работу! Чтобы убедиться, что знаний достаточно, попробуйте порешать реальные тестовые задания в разные компании. Не только на SQL, кстати.
Надеемся, что было полезно. Если знаете другие классные курсы по SQL — делитесь в комментариях!
Читать полностью…
LEFT JOIN
11 March 2024 08:30
Давайте познакомимся (и немного похвастаемся)
Канал растет, приходят новые люди, и мы предполагаем, что не все знают, кто стоит за этим проектом. Хотим об этом напомнить и заодно показать страницу, которую сверстали в Notion для новых сотрудников.
💙 LEFT JOIN — проект команды Valiotti Analytics, которая, как несложно догадаться, занимается аналитикой.
🔵Строим системы аналитики и процессы инжиниринга данных digital-стартапам из Европы, России и США с 2019 года.
🔵 Любим все, что про данные, и делимся любовью с подписчиками канала, слушателями подкаста Data Heroes, в блоге и на YouTube.
🔵 Помогаем войти в IT и познакомиться с SQL с помощью бесплатного курса про работу аналитика и платной email-рассылки про оконные функции.
И так уж получилось, что мы очень уважаем Notion, который используем как внутреннюю «Вики», храним там информацию, распределяем задачи и составляем планы. В общем, если вы сами работаете с ним, вы знаете, какие широкие у него возможности.
Но в правильных руках Notion — это не только удобно, но еще и красиво
🔵 Недавно сделали там страницу про компанию. Рассказали примерно то же, что в этом посте, дали ссылки на наши проекты и кейсы.
🔵 ЦА — в первую очередь потенциальные и новые сотрудники, которых над быстро ввести в курс дела, кто мы такие и чем занимаемся.
🔵 По максимуму использовали возможности верстки Notion, чтобы найти баланс между функциональностью, информативностью и эстетикой.
🔵 Заодно немного упростили жизнь HR. Видите внизу страницы табличку с вакансиями? Она легко обновляется в пару кликов, все вакансии заполняются по заранее сделанному шаблону. Кстати, раз уж об этом заговорили — обратите внимание, может, какая-то вакансия приглянется вам или вашим знакомым.
Кажется, получилось круто, так что решили похвастаться!
Читать полностью…
LEFT JOIN
07 March 2024 08:43
Тест Тьюринга наоборот
Присмотритесь внимательно к рабочим чатам — нет ли там чего-то подозрительного? Всех ли этих людей вы знаете? Вполне возможно, кто-то среди них — не тот, кем кажется. 👀
В мессенджере Slack есть Slackbot — он отправляет напоминалки, автоматические оповещения, если вас упомянули по нику в каком-то чате, и все в таком духе. В общем, стандартный функционал для бота.
💬 Недавно журналист Том Маккей признался в Twitter, когда что в 2022 году он уволился с работы в издании Gizmodo, он поменял ник на Slackbot и поставил такую же, как у бота, аватарку, только более угрюмую. И в таком виде он оставался в рабочем воркспейсе в Slack незамеченным несколько месяцев. В рабочие чаты он не заглядывал, но иногда писал коллегам интересные (на самом деле не очень) факты или советы, выдавая себя за бота.
💬 Обычно роботы пытаются сойти за людей, а тут человек притворялся ботом. Правда, этот тест Тьюринга наоборот он скорее завалил — судя по скриншотам из чатов, бывшие коллеги быстро понимали, что к чему.
Читать полностью…
LEFT JOIN
05 March 2024 08:25
Трансформеры и галлюцинации языковых моделей
Мы уже делились интересными материалами про «устройство» LLM — крутой 3D-моделью или статьей про логику нейросетей. Но эта тема, кажется, неисчерпаема.
Разобраться в ней без технического бекграунда может быть непросто, но есть люди, которые находят способ понятно рассказать про сложные вещи — например, про трансформеры. Нет, не те, про которых Майкл Бэй кино снимал.
🔜 Трансформер — это архитектура нейросетей, представленная командой Google Brain в 2017. Именно благодаря ей LLM сейчас генерируют такие живые, «человеческие» тексты (и не только).
Статья хороша тем, что не просто рассказывает, как они работают, но и показывает — без технических сложностей, наглядно и эффектно. То, что надо если вы с LLM не связаны, в общих чертах понимаете, что они делают, но не совсем представляете себе этот процесс.
Основные тезисы:
💬 Сначала LLM переводит обычный текст на понятный ей язык — то есть разбивает его на токены: отдельные слова или их части. Она «запоминает», какие токены часто встречаются рядом, а какие — редко.
💬 Раньше модели анализировали каждое слово последовательно, одно за другим. Трансформеры оценивают текст целиком и потому работают быстрее и лучше улавливают закономерности. Грубо говоря, это позволяет понимать контекст и различать, что в предложениях «На двери висел замок» и «У реки стоял замок», речь идет о разных замках.
💬 Зная частоту, с которой различные слова обычно встречаются рядом, модель предсказывает, каким должен быть ответ на промпт — то есть какая комбинация слов с наибольшей вероятностью будет уместна.
💬 То, что позволяет хорошо обученной модели генерировать связные и логичные тексты, становится причиной галлюцинаций, когда LLM «выдумывает» несуществующие факты. Она не понимает на самом деле ни смысл запроса, ни смысл своего ответа, а предсказывает, в какой последовательности должны идти слова. Из-за этого она может сослаться на несуществующую страницу в интернете или научную работу. Не со зла, а потому что так уж она устроена.
Читать полностью…
LEFT JOIN
29 February 2024 08:31
О чем я говорю, когда говорю об оптимизаторе SQL-запросов
Парадоксальная ситуация.
Если вы хотите изучить что-то новое, сейчас это сделать легко, как никогда. Не важно, что это — иностранный язык или язык программирования, живопись, брейкданс или история древнего мира. Почти по каждой теме можно найти курсы, литературу или видео.
Но хотя контента много, откопать в сегодняшнем интернете среди откровенной дезинформации и вездесущих SEO-статей что-то полезное бывает сложно.
🔜 Если говорить про материалы про IT, то среди них много устаревших, неактуальных и полных ошибок. Тем круче, когда находишь людей, которые делятся своим реальным опытом и про интересные, но непростые темы.
Автор Xuanwo’s Blog (не будем транскрибировать имя, чтобы не ошибиться) пишет про автоматизацию, хранение данных и распределенные системы. Недавно он выложил первую статью из цикла про создание оптимизатора SQL-запросов. Это компонент БД, который отвечает за определение последовательности выполнения запросов.
🔜 Сам автор говорит, что первый текст — про основы, но надо понимать, что основы основам рознь. Это материал совсем не для новичков. Нужны хорошие практические и теоретические знания, а еще готовность читать про реляционную алгебру и прочие технические штуки. Конечно, автор добавил наглядности с помощью схем, но просто все равно не будет.
Однако, если вам интересна эта тема и вы не боитесь трудностей — материал очень ценный. Не каждый день что-то такое находишь. 🔥
Читать полностью…
LEFT JOIN
27 February 2024 08:34
SQL объединяет
Но не людей, как Nokia, а данные.
Работать было бы проще, если бы всегда приходилось иметь дело с одним аккуратным, упорядоченным датасетом. Но нередко приходится разбираться, как объединить несколько таблиц в одну.
Делимся лонгридом, где автор рассматривает два способа — горизонтальный и вертикальный.
🔜 Горизонтальный — это через join’ы, операторы соединения, про которые, скорее всего, подумали многие из вас.
💬 Есть две таблицы, в которых надо сравнить данные — оценки студентов за летнюю сессию и за зимнюю. Количество строк и имена учащихся в них немного разные — в промежутке между экзаменами кто-то отчислился, а кто-то, наоборот, перевелся с другого потока.
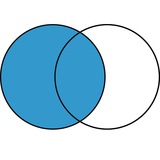
💬 В зависимости от того, какой оператор вы используете, вы можете объединить таблицы так, чтобы собрать в одном месте все данные. Или посмотреть оценки только тех, кто выдержал обе сессии. Или тех, кто сдал экзамены летом и зимой, убрав отчислившихся и добавив новеньких. Какой оператор — inner join, full join, left join, right join — для какой задачи подходит, автор рассказывает и показывает с картинками и примерами кода. И, кстати, делает это очень здорово и без диаграмм Венна.
В итоге вы получите таблицу, которая увеличивается «горизонтально» — то есть столбцов у нее будет больше, чем у таблиц, на основе которых она была создана. Количество строк при этом может либо уменьшиться, либо тоже увеличиться.
🔜 Вертикальный способ — это такой, при котором после слияния таблиц увеличивается число строк. Автор подчеркивает, что это не совсем стандартный термин, а название, которое она использовала для удобства в этом материале.
💬 Например, у нас есть данные об оценках студентов за летнюю сессию из двух разных групп. Нам не нужно разносить из по разным колонкам и сравнивать — их нужно объединить в один длинный список. Вот тут и пригодится один из способов, описанных в статье.
🔜 Текст не претендует на исчерпывающий гайд по всем возможным способам объединения данных, но может быть полезен для тех, кто хочет разобраться в основах.
Читать полностью…
LEFT JOIN
22 February 2024 10:02
EdMetrics: аналитика в онлайн-образовании
Мы часто пишем про данные и аналитику в развлекательном ключе. Находим для вас интересные новости или статьи, делимся полезными приложениями и иногда постим мемы.
Но вообще-то аналитика — это серьезный инструмент, который помогает раскрыть потенциал бизнеса. И это не просто громкий рекламный слоган.
Мы много работаем с EdTech — и небольшими проектами, и международными онлайн-школами из разных стран. И на их примере видим, как правильно настроенная система аналитики меняет все.
🔜 Маркетингу она поможет разобраться, сколько же на самом деле стоит лид, и оцифровать то, что казалось нецифруемым.
🔜 Методистам и преподавателям — понять, почему студенты теряют интерес к учебе или вообще уходят.
🔜 И всем сразу позволит наконец-то вздохнуть свободно, когда данные из кучи Google-таблиц, которые еще и заполнять надо вручную, переедут в нормальную базу.
🔥Круто же? Вот и мы так думаем, поэтому запустили нишевый аналитический проект EdMetrics!
🔵 Его цель — делать мощную аналитику для EdTech’а из России и СНГ. Амбициозно, но мы верим, что справимся, потому что у нас уже есть опыт и главное — ощутимые результаты.
🔵 Мы специализируемся на кастомных системах, которые создаем под запрос заказчика — никаких готовых коробочных решений.
P.S. Если знаете кого-то, кому это может интересно — расскажите им! Mожет быть, благодаря вам, какой-то EdTech-проект перейдет на наш любимый data-driven подход.
Читать полностью…
LEFT JOIN
20 February 2024 08:14
Яндекс Образование запускает студкемпы
Студкемп — это буквально «студенческий лагерь», мероприятие для студентов, где участники собираются на очный интенсив длиной в несколько дней. Они слушают лекции, выполняют практические задания и участвуют в различных проектах.
В этом году Яндекс планирует провести 4 таких студкемпа для старшекурсников технических вузов — от 3-го курса и старше. Набор на первый, который будет посвящен машинному обучению, уже стартовал и продлится до 29 февраля.
🔵 Первый студкемп пройдет 1-13 апреля на территории НИУ ВШЭ. Онлайн участвовать не получится — только очно.
🔵 Участие бесплатное, Яндекс также оплатит проживание и дорогу, но надо пройти отбор — выполнить тестовое задание и пройти собеседование, чтобы подтвердить знание Python и основ ML.
🔵 Занятия будут посвящены работе с LLM и разными типами данных, автоматизации процессов обучения моделей, визуализации результатов. Нетворкинг, общение с будущими коллегами и экспертами и другие достоинства очных тематических мероприятий прилагаются.
Темы следующих студкемпов: Software Engineering, Math and Data Science, Robotics and AI.
Читать полностью…
LEFT JOIN
15 February 2024 09:06
Хотите что-нибудь спросить у своей базы данных?
Недавно мы рассказывали про сервис, который упрощает работу в Excel. Надо просто написать, что и в каких ячейках вам нужно посчитать, и он сгенерирует формулу.
Наверное, никто не удивится, что есть похожий инструмент, который пишет SQL-запросы — Vanna AI.
Принцип работы простой:
1️⃣ Обучаете LLM на ваших данных.
2️⃣ Задаете вопрос. С помощью RAG она подтягивает нужную информацию и генерирует запрос, подходящий конкретно для вашей БД.
RAG (Retrieval Augmented Generation) — это способ функционирования LLM, когда, чтобы дать ответ на вопрос, они берут информацию из внешних источников. В данном случае модель обратится к тому, что знает о вашей базе, чтобы написать корректный SQL-запрос.
Инструмент максимально универсальный
🔵 Общаться с ИИ и, соответственно, через него — с базой можно через Jupiter Notebook, Streamlit, Slack, Flask.
🔵 Работает с любыми базами данных на SQL.
🔵 Open source-версию можно интегрировать с LLM на ваш выбор. Также есть бесплатная версия на GPT 3.5 и платная на GPT-4.
Чтобы настроить Vanna AI, придется совершить некоторые телодвижения, но у проекта очень обширная документация. Так что если готовы погрузиться, особых вопросов возникнуть не должно.
Кстати, у нас есть своя версия такого инструмента — SQL Data Analyst. Это ИИ-ассистент, который тоже помогает писать SQL-запросы.
Читать полностью…
LEFT JOIN
13 February 2024 11:05
Деньги и природа счастья
В тезис «Не в деньгах счастье» поверить бывает сложно, особенно когда денег нет. А теперь еще и ученые доказали, что между финансовым благополучием и уровнем удовлетворенности жизнью связь все же есть.
Этому вопросу посвятили аж три исследования
В них выделяют два виде счастья: гедонистическое и эвдемоническое. Если кратко, первое — это насколько человек получает удовольствие от жизни прямо сейчас, а второе — это насколько человек доволен своей жизнью в целом.
💬 В 2010 экономисты Даниэль Канеман и Ангус Дитон провели исследование по измерению уровня счастья у 1000 американцев с разным уровнем дохода. Их просили каждый день отмечать, насколько они счастливы сейчас и довольны жизнью в целом.
💬 Выяснилось, что высокий доход коррелирует с уровнем эвдемонического счастья. То есть, чем больше денег, тем крепче уверенность, что жизнь удалась. А вот уровень гедонистического счастья выходил на плато, когда опрошенные достигали заработка больше 90 000 долларов в год.
💬 В 2021 новое и более масштабное исследование Мэттью Киллинсгуорта уже на 33 000 человек опровергло существование «гедонистического плато». Участники отмечали уровень удовлетворенности жизнью в уже три раза в день, и у них все виды счастья росли вместе с доходами.
💬 Канеман и Киллингсуорт решили возникшее противоречие достойно: объединили усилия и провели третье исследование. И выяснили любопытный факт — уровень гедонистического счастья действительно выходил на плато у людей с доходом больше 100 000 долларов. Но только у 15% самых несчастливых! То есть, если человек в принципе не очень доволен жизнью, то деньги ситуацию не исправят.
Все три исследования показывают корреляцию между доходами и счастьем, но не дают информации о причинах и следствиях. Может быть, это не деньги делают людей счастливыми, а счастливые люди работают лучше и добиваются успеха? Или вообще какие-то сторонние факторы влияют? 👀
Но так или иначе, даже если счастье на самом деле не в деньгах, эти две вещи точно друг с другом связаны.
Читать полностью…
LEFT JOIN
09 February 2024 09:30
Excelly-AI: переводчик с человеческого на Excel’евский
Про Excel все только и говорят, какой это мощный инструмент и как много у него разных возможностей, о которых некоторые пользователи даже не подозревают.
Их и правда много, но иногда хочется просто по-человечески сказать: «Посчитай среднее в столбцах A и B, а потом найди корреляцию между двумя диапазонами», а не писать длинную сложную формулу. А потом еще разбираться, почему она выдала ошибку на этот раз.
И вот тут на помощь приходит искусственный интеллект в виде сервиса Excelly-AI. Он умеет составлять формулы по запросу, объяснять их значение, трансформировать формулы Excel в формат Google Sheets и обратно, писать код на VBA.
🔜 Выбираете, где у вас составлена таблица — в Excel или Google Sheets.
🔜 Пишете свой запрос на естественном языке, примерно как мы сделали выше, и сервис генерирует формулу.
🔜 Можно загрузить свою таблицу целиком и давать ИИ более конкретные задания. Не «посчитай сумму в столбце А», а «посчитай сумму заказов клиента N».
Бесплатно можно сгенерировать 5 формул в месяц, больше — только по подписке. Всем сомневающимся, стоит ли ее оформлять, команда сервиса предлагает посчитать, сколько денег он может сэкономить.
Правда, для расчета понадобится сначала выяснить, сколько часов в неделю ваши сотрудники тратят на поиск нужных формул в интернете. Не уверены, что много кто собирает подобные данные, но вдруг.
Читать полностью…
LEFT JOIN
07 February 2024 08:54
О любви к таблицам, Linux и забытому софту
А ведь мы с вами пропустили знаменательную дату! 26 января 1983 состоялся релиз софта для создания таблиц Lotus 1-2-3. Сразу после выхода он захватил рынок на ближайшие 10 лет, пока в начале 90-х его не вытеснил Excel.
Lotus позволял не только заполнять таблицы, но и рисовать графики и совершать некоторые операции с данными вроде сортировки. А еще больше расширить функционал можно было с помощью плагинов. Это все сделало крайне популярным и сам Lotus 1-2-3, и IBM PC, для которых он разрабатывался. Так что это не просто программа для табличек, а один из факторов успеха IBM.
Может быть, именно поэтому они поддерживали Lotus 1-2-3 так долго — аж до мая 2013 года. Сейчас это официально abandoware — софт, который больше официально не распространяется производителем.
Но все же Lotus 1-2-3 не забыт! 🔥
Более того, нашелся энтузиаст, который смог запустить его на Linux.
💬 Он искал компилятор и комплект для разработки ПО, чтобы попробовать написать свои плагины для Lotus 1-2-3, а нашел золото — версию для UNIX. Она не только помогла лучше разобраться в работе программы, но и увидеть новую возможность: запустить отметивший 40-летие софт на Linux.
💬Пришлось разобраться с переводом файлов в нужный формат и несовместимыми функциями, а в конце найти способ убедить программу в том, что она лицензионная.
Результат — живой и вполне рабочий Lotus 1-2-3 на Linux. Если нет настроения читать целый лонгрид про взлом древнего софта, можно хотя бы на видео посмотреть, как он выглядит.
Читать полностью…
LEFT JOIN
05 February 2024 08:32
Цена бигмака
В некоторых частях мира «Макдака» нет и не было, в некоторых — был, но закончился. Но даже в странах, которые сеть все же осчастливила своим присутствием, не все ее бургеры одинаково доступны.
На родине McDonald’s в США открыто больше 13 000 ресторанов. Команда кулинарного сайта Pantry & Larder не только отметила каждый на карте, но и посчитала, сколько в них стоят самые знаменитые бургеры — бигмаки.
Как всегда, такие работы интересны тем, что показывают намного больше, чем заявлено в заголовке
Карта визуализирует не просто уровень цен, но и плотность населения и стоимость жизни в разных частях страны. Можно предположить, как сложная логистика в отдаленные северные районы влияет на стоимость продуктов. Даже не зная географию США, на карте легко найти большие города — там бигмаков продается больше всего, но и стоят они в среднем дороже.
Получается этакий взгляд на жизнь в стране через призму фастфуда! 👀
Читать полностью…


 67358
67358