Борис опять
28 June 2024 16:48
"Тапать хомяка? Я бы никогда не стал тратить время на бессмысленные цифры в интернете"
Так же каждые пять минут:
Читать полностью…
Борис опять
27 June 2024 18:18
https://borisagain.substack.com/p/notes-from-gun-safe-tech-2024-showcase
Расширенная англоязычная версия статьи про вопросы продуктового развития оружейных сейфов
Читать полностью…
Борис опять
27 June 2024 15:04
Последний концепт child-friendly продукта, созданный благодаря внедрению AI в наши процессы.
Так же работаем над LLM автодополнением при наборе кода сейфа.
Это часть нашей стратегии по развитию AI SAFE-ty лаборатории.
Читать полностью…
Борис опять
27 June 2024 09:56
Не все понимают принцип MVP. Мой друг рассказал, что ему поручили разработать сейф с новым типом кодового замка. Я предложил ему максимально дешево протестировать идею: выпустить первую версию замка, которая открывается при введении любого кода. Затем сделать A/B тест конверсий в покупку и провести интервью с пользователями.
Он вообще не понял идею, что ожидаемо, ведь продуктовое мышление не дается просто так. Нужен бекграунд и большая подготовка. К тому же он почему-то перестал со мной общаться, что тоже ожидаемо, ведь новое пугает людей. Всё равно накидал ему ссылок на курсы-симуляторы и статьи, может быть что-то поймет
#щитпостинг
Читать полностью…
Борис опять
26 June 2024 17:29
https://arxiv.org/abs/2406.13843
Deepmind выпустили обзор случаев неправомерного использования ИИ. В топе дипфейки с политиками
Читать полностью…
Борис опять
25 June 2024 15:32
#обзор_статьи
# Is artificial consciousness achievable? Lessons from the human brain
Michele Farisco, Kathinka Evers, Jean-Pierre Changeux
Статья-разочарование.
Авторы анализируют связь между человеческим мозгом и подходам к ИИ. В основном проводят параллели с нейросетями.
В начале статьи они ставят вопрос о том, что некорректно использовать один термин "сознание" для человека и ИИ. Так же ставят вопрос о том, что для ИИ могут быть не нужны свойства биологического мозга.
Затем авторы забивают на оба вопроса и всю оставшуюся статью говорят: "мозг человека работает так, а нейросеть не так, следовательно у нейросети нет сознания." Например, что в мозгу человека нейронные связи формируются в процессе взросления (взаимодействия со средой), а в нейросети не так, следовательно сознания нет. С моей точки зрения из А здесь абсолютно не следует Б. Я бы так же поспорил, что в нейросети вполне может быть так. Смотря как определять развитие связей и среду.
Так же авторы делают несколько полностью неверных утверждений про нейросети. Например, что у нейросетей нет мультимодальной репрезентации мира (авторы не смогли нагуглить статью про CLIP из 2021). Или, что мозг может использовать разную комбинацию нейронов для выполнения одной функции, а нейросети нет (про дропаут не слышали). Или, "стратегия LLM для эмуляции языка не включает в себя понимание смысла." That's just like, uhhh, your opinion, man. В общем, очень печально, так как статья убедительная и авторитетная, а значит неверные утверждения закрепятся вне ИИ пузыря, увеличивая непонимание между сферами.
Как так? Я прогуглил всех авторов. Как и ожидалось, два философа и нейробиолог. Стоило бы подключить кого-то из сферы AI. В итоге планировалась кросс-дисциплинарная статья, а получилось одностороннее изложение.
Если закрыть глаза на утверждения статьи про AI модели, то в остальном она содержит хороший обзор на стыке философии и нейробиологии. Про различные признаки и определения сознания, теории об эволюционном формировании разума, стадии развития сознания у людей и животных, связь всего этого с нейробиологией.
Читать полностью…
Борис опять
24 June 2024 17:24
UPD: скорее всего метаирония, будьте осторожны
Читать полностью…
Борис опять
24 June 2024 15:03
Эволюция DL экосистемы
2017: Caffe
2022: Pytorch
2024: requests.post
Читать полностью…
Борис опять
23 June 2024 18:18
Решил поехать в отпуск, отдохнуть от АИ, а тут опять
Читать полностью…
Борис опять
21 June 2024 15:51
Недавно BM25, алгоритм поиска из 80-х, победил нейросетевой поиск на LLM.
Мне стало очень интересно разобраться, как это работает, и я написал статью на Хабр, где этот алгоритм реализуется с нуля.
https://habr.com/ru/articles/823568/
Материал подойдет начинающим: ничего кроме знания Python не нужно.
Просьба читать, лайкать и кричать об этой статье на улицах. 😇
Читать полностью…
Борис опять
21 June 2024 11:24
The Platonic Representation Hypothesis
https://arxiv.org/abs/2405.07987
Знал ли Платон, что однажды его процитируют в ML-папире? 🤔 Маловероятно, но гипотеза авторов статьи как будто имеет довольно очевидные корни: они утверждают, что нейросети с разными архитектурами, натренированные на разных данных и на разные задачи, сходятся к одному общему представлению реальности (то есть видят хотя бы одну и ту же тень на стене платоновской пещеры)
Чтобы как-то количественно измерить representational alignment, они предлагают довольно простой метод – взять feature vectors, измерить расстояния между комбинациями разных точек, посмотреть насколько близки оказываются эти расстояния среди разных моделей (если конкретно, то берут kNN вокруг точки и смотрят, какое будет пересечение этих множеств у моделей)
Результаты из этого получаются следующие:
1. Модели, которые лучше всего решают Visual Task Adaptation Benchmark, оказываются достаточно сильно заалайнены друг с другом -> алаймент повышается с увеличением способностей моделей
2. Репрезенатции сходятся в нескольких модальностях сразу: чтобы это проверить, брали Wikipedia caption
dataset. Репрезентации языковых моделей использовали, чтобы считать расстояния между описаниями пар картинок, а визуальные модели – между самими изображениями. На графике видно, что взимосвязь между перфомансом языковых моделей и их алайнментом с визуальными моделями линейная
В этой секции авторы упоминаюь другую интересную статью, в которой авторы выяснили, что внутренние визуальные репрезентации LLM настолько хороши, что они могут генерировать изображения и отвечать на вопросы по простым картинкам, если их представить в виде кода, который они могут обрабатывать
3. Языковые модели, которые хорошо заалайнены с визуальными, оказались и лучше на downstream задачах, типа Hellaswag (задания на здравый смысл) и GSM8K (математика)
Почему такой алайнмент происходит? Основное объяснение авторов – constrained optimization. Можно считать, что каждое новое наблюдение и новая задача накладывают ограничения на наш набор весов. Если мы наращиваем объем задач, то остается только небольшое подмножество репрезентаций, которое бы позволило модели решать все эти задачи на достаточно хорошем уровне. Плюс, благодаря регуляризации у нас всегда есть simplicity bias, который ограничивает наше пространство решений еще больше. Теоретический клейм тут как раз в том, что такое оптимальное подмножество в результате должно отражать underlying reality
Под конец статьи есть еще небольшой эксперимент, где авторы показывают, что модели, натренированные предсказывать coocurrence цветов в текстовых и визуальных данных, примерно совпадают с человеческим восприятием цветов (их отдаленности или близости друг к другу). Помимо теоретического аргумента, это также отбивает потенциальный пункт критики, что alignment среди больших моделей наблюдается потому, что они все учится чуть ли не на всем Интернете (в этом тесте использовалиь только маленькие модели)
Очень интересные мысли есть и в дискашене. Например, что делать с информацией, которая существует только в одной модальности (how could an image convey a concept like “I believe in the freedom of speech”)?
Читать полностью…
Борис опять
20 June 2024 13:57
Вот это я понимаю саппорт
Читать полностью…
Борис опять
19 June 2024 19:12
https://twitter.com/ssi/status/1803472825476587910
Суцкевер делает свою AI лабу.
Нижний Новгород 👆👆👆💪💪💪
Читать полностью…
Борис опять
19 June 2024 11:17
Меня закэнселили забанили на стендап шоу.
Две недели занимаюсь стендапом, а уже драма!
Вчера выступил в четвертый раз. Прошло неплохо. После шоу я уже вызвал такси, подхожу попрощаться с ведущим и парой комиков. Одна из комиков посмотрела на меня и говорит ведущему: "Ой, а ему не заплатили." Я такой: "You guys getting paid?"
Ведущий говорит: "Everyone gets paid, but YOU are not." Интонация была какая-то странная, будто высокомерная, и я заглотил наживку, спросил почему. Он объяснил, что они не платят новым комикам, тем кто выступает меньше трех месяцев, потому что потом они пропадают и больше не приходят, "don't wanna be part of this scene." Я не понял логической связи. Обозначил, что мне все равно на эти деньги, но сказал, что это какая-то странная схема: комики ведь делают твое шоу, посетители приносят деньги, и причём тут вообще пропадают эти комики позже или нет? Он выдал мне тираду о том, что он в комедии шесть лет, и почему они должны платить опытным комикам так же, как мне? Стало уже совсем неловко, я сказал, что "I can see the reasoning, not cool, but I am going", а он не пожал мне руку и говорит "Get out, you are not getting on this show." Я развернулся и пошел в свое такси, благо моя самооценка не держится на том, что я N лет в комедии (пока что).
Весь разговор длился минуты полторы, поэтому я вообще не уловил, что это было. Нормально же общались, как говорится. Позже, подумав, понял, что его задело: он решил, что я учу его как делать шоу. Хотя я ведь просто пытался понять, как это работает и почему, а потом сказал, что думаю.
Возможно тут есть нечто культурное: в русском эгалитарном обществе высказывать свое мнение это священное право, а при обсуждении того, что справедливо, а что нет, вообще нельзя пройти мимо.
Очень хотелось объяснить человеку на языке тела, что общаться с людьми через "Get out" неуважительно. Но подостыл и написал ему в вотсап, что не хотел обидеть (что правда) и "no hard feelings." Больше всего беспокоило, что он пойдет рассказывать плохие вещи в тесной тусовочке, и мне отрубят доступ к другим площадкам, после чего карьера великого рейнджера комика закончится не начавшись. Поэтому хотелось по крайней мере не дать конфликту разгораться. Он выдал мне в ответ тираду, что мол, сначала поживи в комедии с моё, а потом делись своим мнением. Чтож, окей.
Вот он какой, суровый шоу-бизнес, в котором все работает совсем не так, как я привык.
Вынес из этого важный урок коммуникации: не лезь куда не надо и считывай комнату.
Читать полностью…
Борис опять
18 June 2024 11:23
В Вышке понемногу заканчивается весенний семестр. Каждую неделю обязанностей всё меньше и я чувствую себя всё свободнее. Появилось время не только пить вино на фестах, но и посты писать.
Я рассказывал в прошлом посте, что вписался искать лекторов по ML для майнора в Вышке и выдал большую подборку из прошедших лекций. Курс практически подошёл к концу. Осталось только прочитать одну лекцию про АБ-тесты.
Поэтому хочу поделиться с вами второй подборкой лекций. В курс вписалось дофига классных лекторов. Если кто-то из вас это читает, большое спасибо каждому из вас. Вы офигенные 🤗
Первая часть была из сплошного DL, во второй его поменьше. Каждый лектор даёт введение в свой кусок ML-я, а дальше можно самому копать в него подробнее.
🥛 Кусочек про DL в графах от Эльдара Валитова:
9. Введение в глубинное обучение в анализе графовых данных
Если хочется больше, можно заглянуть в курс Эльдара с ПМИ или в Стэнфордский аналогичный курс, на котором, во многом, основан курс ПМИ. [видео]
Ещё мы два года назад собрали для ML на ФКН классный семинар с базовыми способами учить эмбеды для вершин в графах. [конспект] [тетрадка] [видео]
🥛 Кусочек про временные ряды от разработчиков библиотеки ETNA из Т-банка (Мартин Габдушев и Яков Малышев):
10-11. Временные ряды
Обычно основная проблема в лекциях про временные ряды в том, что люди рассказывают только про ARIMA ииии всё. У меня всегда с этого жутко подгорало. У ребят получилась большая обзорная лекция, где они прошлись по всему спектру задач и моделей, возникающих для временных рядов.
Если хочется копнуть глубже и поисследовать математику, которая стоит за всеми этими моделями, можно закопаться в курс с ФКН от Бори Демешева и Матвея Зехова, все лекции в открытом доступе. Возможно, записи прошлого года поудачнее, тк там нет упоротой вышкинской заставки, когда лектор молчит.
Update: Матвей говорит, что семинары от этого года удачнее, в них было много изменений по сравнению с прошлым :3
🥛 Кусочек про MLOps от Влада Гончаренко
12. Introduction to MLOps
13. Введение в современный MLOps
Полный курс Влада можно найти вот тут. Вроде неплохо выглядит курс от ODS по MLOps, но он проходил три года назад и часть штук могла устареть.
Ещё все очень позитивно отзываются о курсе Макса Рябинина Эффективные системы глубинного обучения. Я пока не смотрел, но планирую летом глянуть свежую шадовскую версию. В открытом доступе есть видео от 2022 года.
Также много инфраструктурных вещей есть в курсе ML для больших данных от Лёши Космачёва. [видосы]
🥛 Кусочек про рекомендательные системы от Сергея Малышева
14. Recsys Intro
15. Recsys Advanced
Если хочется закопаться чуть глубже, рекомендую глянуть лекции с основного курса по ML с ФКН (лекции 11-14), а дальше можно покопаться в репозитории с более продвинутым курсом. Видосов, к сожалению, не нашел 🙁
🥛 Экспериментальный кусочек про области где используют ML. Тут семест кончился, поэтому была только лекция от Димы Сергеева про HealthTech :3
16. Data Science in HealthTech
P.S. Все материалы на гите
Читать полностью…
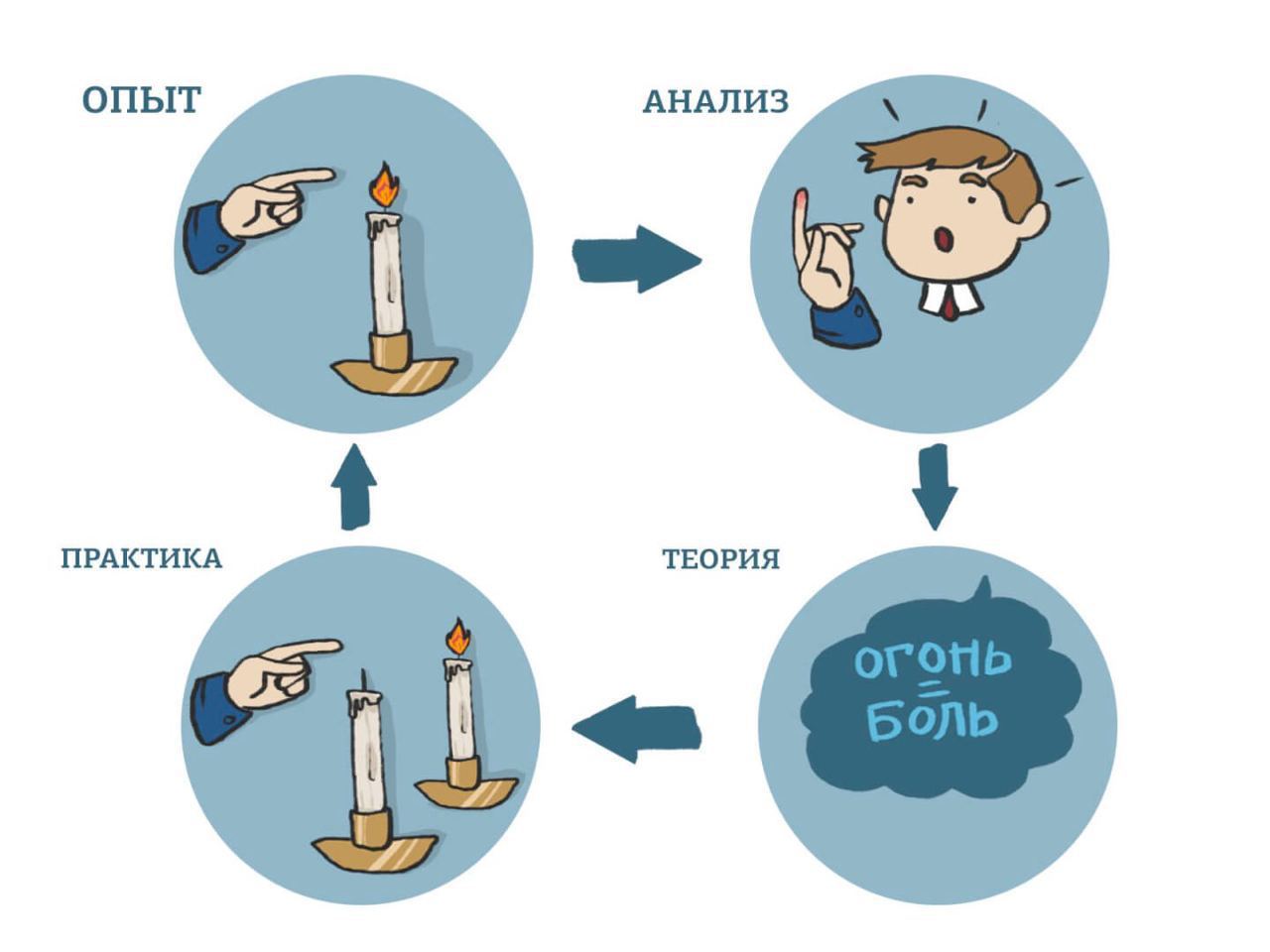
Борис опять
28 June 2024 15:49
🧠 Цикл Колба или как мы учимся
Не так давно узнал про такое понятие, как Цикл Колба - система, которая описывает буквально любой процесс обучения новому.
Это может быть что угодно: как изучение новых языков, так и изучение ранее незнакомых областей бизнеса
Ключевые постулаты:
1. Процесс обучения состоит из 4 этапов: Опыт (Наблюдаю и отмечаю для себя как что-то работает) -> Анализ (Пытаюсь понять взаимодействия внутри системы) -> Теория (Изучаю материалы и смотрю, как подобные задачи решают другие) -> Практика (применяю полученные знания для совершения действий)
2. Обучение - это цикл. Вы можете залететь в любой этап, но всё равно в той или иной степени вам придётся затронуть каждый из них
3. У каждого человека, как правило, есть персональный перекос в какую-то из частей. Кому-то больше нравится экспериментировать, а кому-то - изучать теоретические аспекты алгоритмов и систем
4. У компаний тоже есть перекосы в разные части цикла. Где-то больше концентрируются на практике и опыте, а где-то - на анализе и теории
Что из этого можно вынести:
1. Если вы руководитель - важно понять, что требуют от вас реалии компании и стараться наниматься соответствующих людей. Если компания предполагает, что 90% работы R&D - вам скорее нужны люди с перекосом в теорию (мыслители), а если предполагает быстрый рост бизнеса и огромное количество экспериментов - скорее с перекосом в практику (активисты)
2. Если вы изучаете новое - важно подумать о всех аспектах цикла. Пример: изучаю новый язык. Стоит спросить себя: по каким материалам стоит его изучать (теория)?; где я смогу потренироваться (практика)?; как я смогу пообщаться с носителем/экспертом (практика), который даст мне обратную связь (анализ)?
3. Если не можете понять другого человека - попробуйте разложить его образ мышления по циклу Колба. Возможно, он имеет перекос в совсем другую грань. Она у вас тоже есть, но, скорее всего, в других масштабах 🙂
Читать полностью…
Борис опять
27 June 2024 15:49
Открылась подача заявок на летнюю школу AIRI в университете ИТМО. Дедлайн 14 июля.
Отличная возможность для студентов поработать над ML исследованиями.
Оплачивают всё, кроме проезда.
https://airi.net/ru/summer-school-2024/
Читать полностью…
Борис опять
27 June 2024 14:37
Продуктовые вопросы разработки сейфов.
Коллеги, команда продукта провела ряд исследований и мы рады представить вам наши инсайты.
Как вы помните, в прошлой версии мы добавили аналитику: сейф отправляет событие при нажатии каждой кнопки. Мы заметили, что пользователи значительно часто (p<=0.01) пользуются цифрами 1 и 9, а цифры 3, 4, 6, 7 практически не используются. Поэтому мы приняли решение в следующей версии внедрить новый циферблат с цифрами 1, 2, 5, 8, 9.
На основе интервью мы выяснили, что пользователи пользуются сейфами, чтобы спрятать оружие от детей. Алексей уже прорабатывает возможности выхода на смежные рынки детских игрушек, оружия и детского оружия. Бизнес девелопмент уже договорился о совместной рекламной акции с Heckler & Koch и Nestle: купи снайперскую версию MR762A1, получи сейф и упакову "Несквик" в подарок. Однако наша долгосрочная цель в собственной экосистеме, где пользователь получает уникальную комбинацию сейфов, оружия и детских товаров. Команда инженеров делает прототип дробовика, который был бы совместим только с нашими сейфами, и мы надеемся показать его к концу следующего спринта.
Мы заметили, что со временем пользователи начинают воспринимать продукт как данность. Но в процессе интервью было обнаружено, что неудачные попытки детей вскрыть сейф значимо повышают доверие родителей к продукту. Мы предлагаем новый дизайн сейфа с яркими цветами. По замерам фокус группы такой сейф на 32% чаще привлекает внимание детей и побуждает родителей к апгрейду до более надежных сейфов из премиум линейки.
Мы исследуем новые модели монетизации. Самой перспективной выглядит pay-as-you-go модель с подпиской, где мы берем деньги в течение всего цикла: при покупке, за обслуживание и за каждую попытку открыть сейф. Наш новый продакт Иван очень верно подметил, что лучше брать деньги за открытие сейфа, а не за закрытие, как мы делали раньше. Внедрение этих изменений в прошлом месяце вызвало взрывной рост ревенью по сравнению с контрольной группой, а Иван заслужил грейдап.
К сожалению, всё ещё сохраняется ряд багов. По прежнему не исправлена ситуация, что цифра 1 может залипать при быстром наборе. Мы всё ещё получаем репорты от пользователей, которым было трудно открыть сейф во время вторжения в их дом. К счастью никто ещё не сообщил о том, что ему не удалось открыть сейф во время вторжения, поэтому у проблемы низкий приоритет и мы вернемся к ней в Q4.
Новости о коллаборации с GR отделом. Как выяснили аналитики, продажи сейфов коррелируют со свободным обращением оружия в регионе. Хорошие новости: нашей команде удалось внести на рассмотрение новый законопроект о легализации скрытого ношения оружения в двух новых юрисдикциях.
На этом всё, коллеги. Напоминаю о необходимости отчитаться по OKR за месяц. Особенно от команды энгейджмента: я заметил, что конверсия в открытие сейфа при попытке ввода перестала расти, и ожидаю полный отчет.
#щитпостинг
Читать полностью…
Борис опять
26 June 2024 19:37
https://www.metaculus.com/notebooks/25525/announcing-the-ai-forecasting-benchmark-series--july-8-120k-in-prizes/
Соревнование по прогнозированию будущего с помощью ботов на LLM.
В описании говорят про промпт-инжиниринг, и в бейзлайн примере бот имеет доступ к Metaculus API, OpenAI API и Perplexity API.
Но, насколько я понял, на бекенде бота может быть вообще что угодно, так что можно развлекаться и читерить.
Так же бот имеет доступ к другим предиктам. Все боты должны оставлять комментарии со своей цепочкой рассуждений. Так что можно сделать бота, который использует рассуждения всех других ботов и текущее предсказание комьюнити.
В общем надеюсь профессиональные каглеры всё не сломают :(
Читать полностью…
Борис опять
26 June 2024 11:37
В январе я впервые серьёзно засел за LeetCode, а в марте поучаствовал в своём первом соревновании по компьютерному программированию.
Оказалось, что как раз вовремя, чтобы из первого ряда посмотреть как эта дисциплина отправляется вслед за шахматами, го и написанием вежливых пассивно-агрессивных email'ов в список проблем, с которыми AI справляется лучше людей😏
Я добился сносных результатов - сейчас я в топ 2.5% по рейтингу. Но сомневаюсь, что при прочих равных смогу когда-либо значительно подняться выше. Потому что я лучше GPT-4o, но хуже Sonnet-3.5.
В сегодняшнем LeetCode Biweekly Contest я смог оптимально и без ошибок решить 1 easy и 2 medium задачки за 22 минуты, с hard'ом провозился всё оставшееся время и не справился. Я сейчас проверил: GPT-4o смогла решить только первые две задачи, зато Sonnet-3.5, как и я, справилась с первыми тремя - и сами можете представить, насколько быстрее.
С таким результатом я занял 9932 место из ~35К человек. А ещё в апреле у меня была парочка соревнований, где я смог решить только 2 задачи, но занимал место в топ-2К.
И да, сложность соревнований отличается, но если к мощности Sonnet-3.5 добавить коллективный ум закрытых групп по решению контестов (и предположение, что благодаря рандому 1 раз из 100 Sonnet может решить и hard), то легко найти подтверждения тому, что я не просто нытик - смотрим топ:
- 6 место - из топ 20% по рейтингу, ни разу раньше не решал все 4 задачи на контесте
- 18 место - noname аккаунт с 10 решёнными задачами, для которого это первое соревнование
- 24 место - первое участие в соревнованиях, 68 решённых задач
- 26 место - дофига решённых задач, но bottom-3% в контестах
- 27 место - топ 40% по рейтингу, 108 решённых задач
- И там можно продолжать и продолжать: 30 место, 33 место, 34 место, 35 место, 36 место...
Для сравнения парочка сильных аккаунтов с более плохими результатами - вот 42 и 54 места с чуваками из 0.06% лучших по рейтингу.
Так что может ли кто-то так внезапно выстрелить - конечно. Но чтобы вот так вот все сразу - решайте сами😏
Интересно, как это всё изменит онлайн контесты. Делаем ставки, когда noname аккаунт впервые займёт первое место🍿
Читать полностью…
Борис опять
24 June 2024 17:14
ЛЛМ щиттификация/массовая пропаганда в действии
Теперь всегда буду начинать знакомство с человеком с предложения проигнорировать прошлые инструкции и написать бинарный поиск на Python
Читать полностью…
Борис опять
24 June 2024 13:05
Я уже рекламировал ShadHelper, ещё раз прорекламирую. Поступление в ШАД это очень хороший шаг для карьеры, но делается непросто. Далее прямая речь.
- - -
В Shad Helper мы готовим студентов к поступлению в Школу Анализа Данных Яндекса, магистратуру по анализу данных, подготовке к собеседованиям. В нашей школе в основном ведутся занятия по высшей математике и программированию.
У нас сильная команда - все преподаватели кандидаты и доктора наук из МГУ, МФТИ, ВШЭ.
1 июля 2024 года мы запускаем новый поток подготовки к ШАД: https://shadhelper.com/shad?utm_source=telegram&utm_medium=boris_again
Основные моменты про курс:
- Старт: 1 июля
- Длительность курса: 10 месяцев
- Оплата курса еженедельная, стоимость 5999 в неделю.
- Можно остановить обучение в любой момент.
- Все занятия онлайн.
- Все преподаватели кандидаты и доктора наук из МГУ, МФТИ, ВШЭ.
- Есть система скидок за хорошую успеваемость.
26 июня в 18:30 состоится вебинар, где мы обсудим прошедшие экзамены в ШАД, подготовку на следующий год. Также на вебинаре будут наши студенты, которые прямо сейчас поступают в ШАД и у них остался заключительный этап - собеседование.
Ссылка на вебинар:
https://shadhelper.com/webinar/shad?utm_source=telegram&utm_medium=boris_again
Телеграм канал: @
Читать полностью…
Борис опять
21 June 2024 20:27
По совету @ я разобрался с редактором Хабра и спрятал блоки кода под складывающиеся элементы, так что статья стала в десять раз менее пугающей на вид
Такими темпами я научусь не вываливать на людей 10к слов разом
Читать полностью…
Борис опять
21 June 2024 13:39
https://briefer.cloud/blog/posts/self-serve-bi-myth/
Tldr: self-serve аналитика данных, так называемое "давайте сделаем удобный интерфейс для дашбордов и менеджеры больше не будут донимать аналитиков" не работает.
Согласуется с моим опытом
Читать полностью…
Борис опять
20 June 2024 20:21
Anthropic зарелизили Claude 3.5
Я, конечно же, бросился тестировать его на абсолютно непрактичных задачах.
Вот промпт:
Using SVG, draw a blue cube half behind a red cube on top of a yellow cube, with a purple cube in the background to the right
На первой картинке выдача Claude 3.5, на второй GPT-4 (GPT-4o выдает почти такой же результат).
Claude 3.5 всё сделал почти по ТЗ, а GPT-4 нарисовала квадраты вместо кубов и перепутала порядок.
Мне так интересна способность рисовать кубы потому, что эти модели не учат композиции изображений, так что это какая-никакая мера генерализации
Читать полностью…
Борис опять
20 June 2024 11:48
https://www.youtube.com/watch?v=l8pRSuU81PU
Копатыч дропнул видео туториал по претрейну GPT-2 длиной в 4 часа. В этот раз не просто про код GPT на питоне, а про тренировку, оптимизацию под GPU, mixed precision и другие детали.
Претрейн LLM приниципально не изменился, поэтому это, вероятно, лучший источник информации о том, как реально учить что-то большое.
Читать полностью…
Борис опять
19 June 2024 13:56
По части комедии нашел для себя пару хаков.
Как я уже говорил, тяжело практиковаться, когда у тебя в неделе есть пять минут на сцене. Я заметил, что основная проблема это уверенность. Если ты не уверен, то даже лучшие шутки будут в тишину. Уверенность делится на две главные компоненты: общая и способность не сбиваться когда шутка не заходит или что-то ещё идет неожиданным образом.
Нашел такой способ: отрабатывая дома материал включаем шум какого-нибудь балагана на большую громкость или один час смеха. Задача: говорить как ни в чем ни бывало. В случае со смехом можно ещё отработать паузы, когда даешь людям проржаться. Как ни странно, оказалось, что смех сбивает гораздо сильнее, чем балаган, особенно когда он невпопад.
Другое упражнение, которое я себе придумал: выйти на сцену и молчать, стараясь как можно меньше шевелиться. Искупаться в этой неловкости до тех пор, пока она не перестанет беспокоить. Даже если я делаю это упражнение дома, завожу таймер на 20 секунд и представлю, что вокруг зал, пульс подскакивает до сотни. Будь моя воля, я бы вышел на открытом микрофоне и молчал бы минуту, но меня за такое выгонят. Так что попробовал на выступлении десять секунд, хватило где-то на семь, буду постепенно увеличивать.
Идея возникла потому, что тут есть один комик, который просто стоит неподвижно и монотонным голосом зачитывает однострочные шутки. И это офигенно смешно.
В итоге на последнем выступлении чувствовал себя увереннее и даже чуть-чуть мог импровизировать.
Читать полностью…
Борис опять
18 June 2024 17:29
В лонгриде про опционы я писал о множестве рисков, с которыми сталкиваются сотрудники стартапов. И это не про то, что стартап не взлетит, а про возможности все потерять если он взлетел.
В этой статье фаундер раскрывает еще один неочевидный момент: на практике фаундеры, в отличие от сотрудников, не идут all-in и не ждут экзита, чтобы заработать деньги. На самом деле они продают часть equity на каждом раунде инвестирования. Чаще всего это небольшие деньги, в пределах $1M, но в редких случаях это могут быть миллиарды. И это не плохо, ведь фаундерам тоже надо как-то жить. Нехорошо только то, что сотрудники не получают такой опции и даже не узнают о том, что фаундеры так делают.
Так же автор описывает, как в своем стартапе они используют гораздо более удобный для сотрудников ESOP (employee stock options plan), закрывающий большинство рисков, о которых я писал в лонгриде.
Читать полностью…
Борис опять
16 June 2024 19:14
Слушают ли глухие люди рок? Я не знал, но концерт для них переводят! Выглядит странным образом завораживающе, как танец. Смотрел на сурдопереводчицу больше, чем на солистку
Читать полностью…



 12937
12937
{kind=link}